
ISO/IEC JTC 1/SC34 N446
| Title: | Topic Maps -- Overview and Basic Concepts |
|---|---|
| Source: | Steve Pepper, Motomu Naito, JTC1 / SC34 |
| Project: | ISO 13250: Topic Maps |
| Project editor: | Steven R. Newcomb, Michel Biezunski, Martin Bryan |
| Status: | Working Draft |
| Action: | For Review and Comment |
| Date: | 2003-11-03 |
| Summary: | |
| Distribution: | SC34 and Liaisons |
| Refer to: | |
| Supercedes: | |
| Reply to: | Dr. James David Mason (ISO/IEC JTC1/SC34 Chairman) Y-12 National Security Complex Information Technology Services Bldg. 9113 M.S. 8208 Oak Ridge, TN 37831-8208 U.S.A. Telephone: +1 865 574-6973 Facsimile: +1 865 574-1896 E-mail: mailto:mxm@y12.doe.gov http://www.y12.doe.gov/sgml/sc34/sc34oldhome.htm Mrs. Sara Desautels, ISO/IEC JTC 1/SC 34 Secretariat American National Standards Institute 25 West 43rd Street New York, NY 10036 Tel: +1 212 642-4937 Fax: +1 212 840-2298 E-mail: sdesaute@ansi.org |
|
Ed. note: This draft of ISO 13250-1 has been produced as a strawman in order facilitate a decision by the Working Group on what form this Part should take. The original proposal for a Part 1 was motivated by the perceived need for an introduction to the fundamental concepts of Topic Maps that could be read in isolation from the definition of the Data Model (which is the subject of Part 2). While there cannot be any doubt that the Data Model needs to be at the heart of the standard, it should also be recognized that most of the readers of 13250 will not be implementors. Those people need a clear presentation of the concepts that is not intermixed with data modelling concepts like item types and properties. The problem that has to be solved is how to reconcile these two needs without introducing redundancy. This draft is an attempt on the part of the editors of Part 1 to show what the solution might look like. It was deliberately written without reference to the current draft of Part 2, in order to be able to assess the validity of the approach originally envisaged. (It was also left incomplete in order not to spend unnecessary time.) There is now a large amount of overlap between Parts 1 and 2, but this was to be expected. The questions we wished to raise, and hope to have answered at the Philadelphia meeting of WG3, are the following:
A decision not to include a separate presentation of the fundamental concepts will call the need for a separate Part 1 into question. The minutes of the Montreal meeting of WG3 recommended the editors to follow the model of ISO 8879, which includes a tutorial in Annex A. We wish to point out that this model is only partly relevant, since the annex in question actually contains a reprint of a rather old paper describing the general principles of generic markup, rather than a tutorial based on the standard. For the purpose of this strawman, we have simply copied the Gentle Introduction from the XTM Specification. If a decision is taken to include such a tutorial, we envisage a rewrite that contains more syntax examples and is more in line with the concepts as currently defined and understood by WG3. N.B. Since the current document is just a strawman, no attempt has been made to ensure that it follows the latest ISO rules in terms of document structure. |
ISO (the International Organization for Standardization) and IEC (the International Electrotechnical Commission) form the specialized system for worldwide standardization. National bodies that are members of ISO or IEC participate in the development of International Standards through technical committees established by the respective organization to deal with particular fields of technical activity. ISO and IEC technical committees collaborate in fields of mutual interest. Other international organizations, governmental and non-governmental, in liaison with ISO and IEC, also take part in the work.
In the field of information technology, ISO and IEC have established a joint technical committee, ISO/IEC JTC 1. Draft International Standards adopted by the joint technical committee are circulated to national bodies for voting. Publication as an International Standard requires approval by at least 75% of the national bodies casting a vote.
International Standard ISO/IEC 13250-1 was prepared by Joint Technical Committee 1 JTC1, Information technology, Subcommittee SC34, Document description and processing languages.
International Standard ISO/IEC 13250 Topic Maps consists of several parts. This Internal Standard ISO/IEC 13250-1 is included in it. A series of this standard provides definitions, requirements, and so on concerning Topic Maps.
Topic maps enable multiple, concurrent views of sets of information objects. The structural nature of these views is unconstrained; they may reflect an object oriented approach, or they may be relational, hierarchical, ordered, unordered, or any combination of the foregoing. Moreover, an unlimited number of topic maps may be overlaid on a given set of information resources. Topic Maps realize the collocation of information about subjects.
Topic maps can be used:
This International Standard does not require or disallow the use of any scheme for addressing information objects. Except for the requirement that topic map documents themselves be expressed using XML (or WebSGML), using the syntax described herein, neither does it require or disallow the use of any notation used to express information.
This clause defines the scope of this International standard. It should not be confused with the concept of "scope" defined in 13250-2, which only applies in the context of Topic Maps.
ISO/IEC 13250 Topic Maps consists of the following parts.
This Part of the International Standard provides an overview of each part and how the parts fit together. It also describes and defines the fundamental concepts of Topic Maps.
|
Ed. note: Look at ISO 10303, where Part 1 also presents Fundamental Concepts, in order to see how it might be done in this standard. Status of HyTM and Reference Model as parts of ISO 13250 has not yet been clarified. |
The following standards contain provisions which, through reference in this text, constitute provisions of this International Standard. At the time of publication, the editions indicated were valid. All standards are subject to revision, and parties to agreements based on this International Standard are encouraged to investigate the possibility of applying the most recent editions of the standards indicated below. Members of IEC and ISO maintain registers of currently valid International Standards.
ISO 8879:1997 Information processing ---- Text and office systems ---- Standard Generalized Markup Language (SGML)
ISO 8879:1986 /Cor2:1999
ISO/IEC CD 18048 Topic Maps Query Language (TMQL)
ISO/IEC PDTR 19756 Topic Maps Constraint Language (TMCL)
|
Ed. note: The following text has been taken from the Roadmap document. The editors request feedback on the level of detail required in this overview. |
ISO/IEC 13250-1 provides an overview of each part and how the parts fit together. It also describes and defines the fundamental concepts of Topic Maps.
ISO/IEC 13250-2 specifies a data model for topic maps. It defines the abstract structure of topic maps, using the information set formalism, and to some extent their interpretation, using prose. The rules for merging in topic maps are also defined, as are some fundamental published subjects.
13250-2 provides specification for 13250-3,4,5 and foundation for ISO/IEC 18048 Topic Maps Query Language (TMQL) and ISO/IEC 19756 Topic Maps Constraint Language (TMCL)
ISO/IEC 13250-3 defines the XML Topic Maps 1.1 (XTM) interchange syntax for topic maps, a syntax based on XML, XLink, and URIs. The allowed syntactical expressions in XTM documents are constrained using a DTD and prose, and their interpretation is defined using 13250-2. Note that this is only a syntax specification; what the syntax represents is defined by 13250-2.
ISO/IEC 13250-3 will replace [XTM1.0] as the official definition of the XTM syntax once it is adopted by ISO as part of the revised ISO 13250 standard.
ISO/IEC 13250-4 defines the HyTime Topic Maps (HyTM)) interchange syntax for topic maps, a syntax based on SGML and HyTime.
ISO/IEC 13250-5 defines a means to express a topic map processed according to the processing rules defined in ISO 13250-2: Topic Maps -- Data Model in a canonical form. The canonicalisation is based on the model defined by ISO 13250-2 and henceforth referred to as the Topic Maps Data Model. Such a canonical form enable the instance of the Topic Maps Data Model constructed by one topic map processor to be directly compared to that constructed by another topic map processor.
Canonicalisation is the process by which a data model is reduced to a serialised form such that two logically equivalent data model instances result in an identical byte-by-byte serialization.
ISO/IEC 13250-6 provides a basis for evaluating syntaxes and data models for Topic Maps, including but not limited to those specified by 13250-2, 13250-3, 13250-4, and 13250-5, in terms of their ability to arrive at one proxy for each unique subject. The state of having one proxy for each unique subject, also known as the "Subject Location Uniqueness Objective," is an objective for only some subjects in any given data model or syntax.
ISO/IEC 13250-6 makes the underlying abstraction of Topic Maps explicit and does not extend or limit another part of ISO/IEC 13250.
The relationship of each part and how they fit together is shown in the figure below.
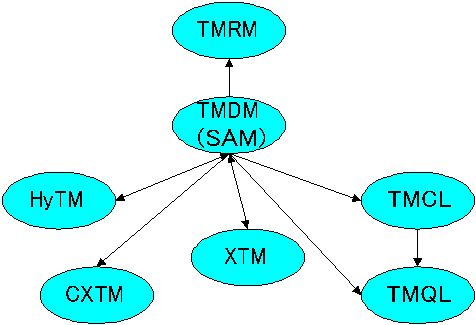
Figure 1: Relationship of the parts of ISO 13250
|
Ed. note: Redraw graphic to distinguish between 13250, 18047 and 19756. (Uses different arrow types to distinguish between dependencies and data flow?) Status of RM and HyTM? |
Any piece of information can be said to be "about" one or more subjects. At the heart of the Topic Maps paradigm is the notion that the most effective way of organizing information - at least for most purposes - is around those subjects.
A subject can be an individual, like Isaac Newton, the apple that fell on his head, or a document (such as this one); it may be a class of individuals, like scientists, fruits, or ISO standards; it may also be a more abstract concept like gravity or inevitability. In short, a subject can be any subject of discourse that an author wishes to identify, name, represent, or otherwise make assertions about.
Subject
Anything whatsoever, regardless of whether it exists or has any other specific characteristics, about which anything whatsoever may be asserted by any means whatsoever.

Figure 2: A subject
Applications deal with subjects through formal representations using symbols as proxies. In Topic Maps such proxies are called topics. A topic is thus the representation, inside some application, of a unique, clearly identified, and non-ambiguous subject.
Topic
A symbol used within a topic map to represent a subject.
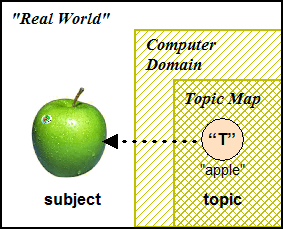
Figure 3: A topic and the subject it represents
A topic map is a collection of topics and statements made about the subjects they represent.
By definition every topic represents a single subject (although that subject may itself consist of other subjects, as in "The members of the United Nations"). A subject, on the other hand, may be represented by more than one topic. This is often the case with multiple topic maps that cover the same universe of discourse.
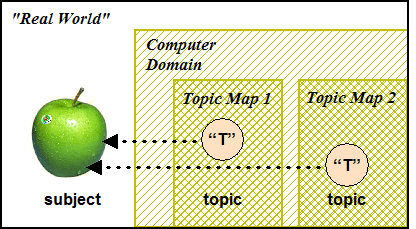
Figure 4: Multiple topics that represent the same subject
However, within a single topic map, the goal is that there should be only one topic per subject, in order to ensure that everything that is known about a given subject is available from a single location (i.e., topic) within that map. This goal is called the collocation objective.
The collocation objective also applies when two topic maps are merged. Topics that represent the same subject must be merged to a single topic, which has the union of the characteristics of the original topics.
Collocation objective
[fixme definition]
To make it possible to achieve the collocation objective, Topic Maps provides very specific mechanisms for establishing the identity of subjects.
Subject identity is a set of properties of a topic that enable applications (and humans) to know which subject the topic represents and, in particular, to know when two topics represent the same subject and must therefore be merged.
Because it is concerned with information management, Topic Maps recognizes a fundamental ontological distinction between "subjects in general" and a particular subset of subjects, namely information resources, such as documents.
Information resource
A resource that can be represented as a sequence of bytes and thus could potentially be retrieved over a network.
The distinguishing property of information resources vis-à-vis any other kind of subject is that they have a location within some network and thus an address which can be used to uniquely identify them. All other subjects are non-network retrievable and do not have addresses.
In recognition of the distinction between addressable subjects (i.e., information resources) and subjects in general (i.e., information resources and non-addressable subjects), Topic Maps provides two mechanisms for specifying subject identity, both of which use locators.
A subject locator is used to identify an information resource directly via its address.
Subject locator
A locator that refers to an information resource that is the subject of a topic.
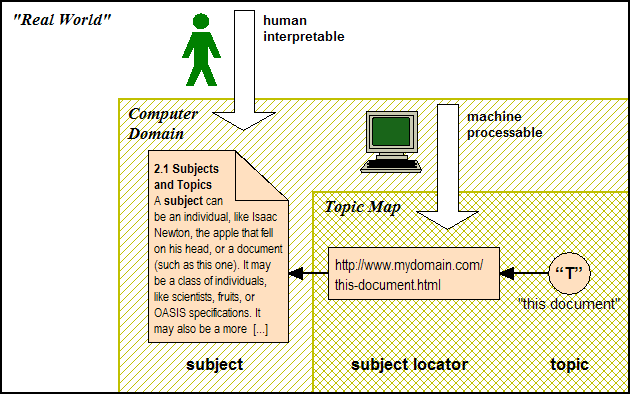
Figure 5: Identifying an (addressable) subject directly using a subject locator
Subjects that are "outside the system" and thus cannot be identified directly can be identified indirectly via a subject indicator.
Subject indicator
An information resource that indicates the identity of a subject to a human being.
A subject indicator can be any kind of information resource that can be interpreted by a human and that provides sufficient indication of the identity of a subject to be able to distinguish it from other subjects for the purpose of some application. Since a subject indicator is an information resource, it has an address that can be used as a subject identifier.
Subject identifier
A locator that refers to a subject indicator.
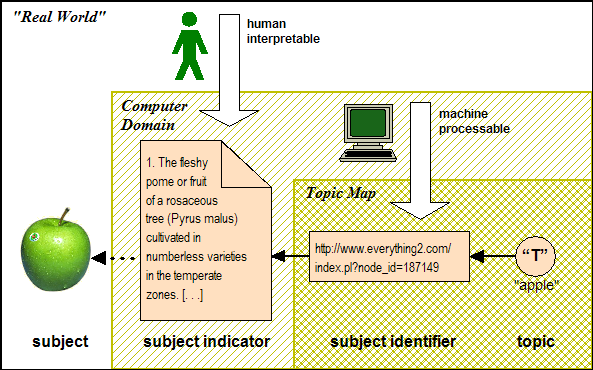
Figure 6: Identifying an arbitrary subject indirectly using a subject identifier and a subject indicator
Locators can thus be used in one of two ways to identify a subject: directly, as a subject locator, and indirectly, as a subject identifier. In Topic Maps it is always clear, both in the data model and in conforming syntaxes, when a locator is being used in one or the other of these roles, and when it is simply being used as a locator.
[fixme]
[fixme]
[fixme]
[fixme]
[fixme]
[fixme]
As a way of making concrete the use of the topic map notation defined in this specification, consider the following example. Let us suppose that we wish to record, in a device-independent and implementation-independent way, the kind of information about the subject matter of a document that might be included in the subject index to an encyclopedia in electronic form.
For various subjects — for example, William Shakespeare, Ben Jonson, their plays Hamlet and Volpone, and the towns of London and Stratford, among thousands of others — we will wish to record all of the locations in the encyclopedia — whether passages of text, or images, or sound recordings in a multi-media encyclopedia — where they are discussed, depicted, or mentioned. We will speak of these locations as occurrences of these subjects. Note that different occurrences may relate to their subject in very different ways, which we would like to distinguish. In-depth discussions, brief mentions, and illustrations may need to be distinguished in order to allow the users to find more quickly what they need.
The encyclopedia we are working with exists in electronic form, so every occurrence of a subject is an electronic resource, for which we can compute an address. (Without going into detail about the nature of the address, we define an address as an expression, usually short, which allows a suitable processor to locate a resource.) They are thus addressable information resources.
The playwrights William Shakespeare and Ben Jonson, by contrast, are not addressable resources: they are not electronic artifacts at all, but real human beings. In order to represent the link between an occurrence of a subject and the subject itself, we would like simply to point to each in turn and say “this location discusses this subject” (or perform the equivalent gestures in some electronic notation, by giving the address of the subject, the address of the occurrence, and describing the relation between them using markup).
Because not all subjects are electronic artifacts, however, we cannot provide an address for the subject. Instead, we provide an electronic surrogate for the subject, which (being electronic) can have an address. This surrogate we call a topic. Every topic acts as a surrogate for some subject. We say that the topic “reifies” the subject — or makes the subject “real” for the system. The creation of a topic that reifies a subject enables the system to manipulate, process, and assign characteristics to the subject by manipulating, processing, and assigning characteristics to the topic that reifies it. When we need an address for the subject, we give the address of a topic which reifies it, and acts as its surrogate within the system.
(Where it will not lead to confusion, we will sometimes use the terms topic and subject interchangeably; since each topic reifies some subject, and since for each subject we can construct a topic to reify it, the difference is not always important.)
Since our entire collection of subject-index information provides a sort of map of the encyclopedia, showing where various topics are mentioned and discussed, we call our electronic representation of the subject index a topic map.
Topics representing several of William Shakespeare's plays might look like this:
<topic id="hamlet">
<instanceOf><topicRef xlink:href="#play"/></instanceOf>
<baseName>
<baseNameString>Hamlet, Prince of Denmark</baseNameString>
</baseName>
<occurrence>
<instanceOf><topicRef xlink:href="#plain-text-format"/></instanceOf>
<resourceRef
xlink:href="ftp://www.gutenberg.org/pub/gutenberg/etext97/1ws2610.txt"/>
</occurrence>
</topic>
<topic id="tempest">
<instanceOf><topicRef xlink:href="#play"/></instanceOf>
<baseName>
<baseNameString>The Tempest</baseNameString>
</baseName>
<occurrence>
<instanceOf><topicRef xlink:href="#plain-text-format"/></instanceOf>
<resourceRef
xlink:href="ftp://www.gutenberg.org/pub/gutenberg/etext97/1ws4110.txt"/>
</occurrence>
</topic>
Note: For brevity, examples of URIs in this
specification sometimes include only a fragment identifier (e.g. #play above). In such cases, it is assumed that these identifiers refer to a
<topic> element elsewhere in the same topic map with an
“id” attribute value that matches the fragment identifier.
It is often useful in thesauri and subject indexes to indicate relationships among the subjects: Hamlet and The Tempest are both examples of plays, Shakespeare is their author, Rosencrantz and Guildenstern are characters in the play Hamlet, etc. In traditional reference works, these kinds of relationships are used to guide the compiler in the creation of cross references. Note that these relationships hold not among the occurrences of the subjects but among the subjects themselves; an electronic representation of them can be wholly independent of the occurrences and might be applied to very different collections of resources. The electronic representation of relationships among subjects, of course, will take the form of relationships, or associations, among the topics that reify those subjects.
An association representing the relationship between Shakespeare and the play Hamlet might look like this:
<association>
<instanceOf><topicRef xlink:href="#written-by"/></instanceOf>
<member>
<roleSpec><topicRef xlink:href="#author"/></roleSpec>
<topicRef xlink:href="#shakespeare"/>
</member>
<member>
<roleSpec><topicRef xlink:href="#work"/></roleSpec>
<topicRef xlink:href="#hamlet"/>
</member>
</association>
Because associations express relationships they are inherently multidirectional: If “Hamlet was written by Shakespeare”, it automatically follows that “Shakespeare wrote Hamlet”; it is one and the same relationship expressed in slightly different ways. Instead of directionality, associations use roles to distinguish between the various forms of involvement members have in them. Thus the example above may be serialized using natural language as follows: “There exists a 'written by' relationship between Shakespeare (playing the role of 'author') and Hamlet (playing the role of 'work').” Relationships may involve one, two, or more roles.
There is no intrinsic limit to the kinds of relationships among subjects which we can record in this way; for some purposes, lived in and example of will suffice; for other purposes, very different relationships among subjects will be of interest.
Because topics and their relationships can be described independently of their occurrences in any given set of information resources, it may be expected that a given set of topics may be connected, in different applications, with many different sets of information resources. Conversely, one set of information resources may be described by many different topic maps. Different topic maps may define topics for the same subject; it will be important, in practice, to be able to merge topics which denote the same subject.
At an abstract level, we can say that our encyclopedia consists of a set of addressable information resources, each of which may be located inside of some larger addressable information resource and each of which pertains to one or more subjects. Our subject index consists of the following three things:
We use the term topic map to denote any collection of such things. Note that since subjects, as we have defined them, include anything human beings want to think about, discuss, or represent in electronic form, there is no mechanical test to determine whether two subjects are identical or not, or whether two topics reify the same subject or not. Accordingly, the subjects themselves make no appearance in the formal description just given. Nor do we attempt to restrict the nature of the relationships between topics and their occurrences, or between topics and other topics. For this reason, the formalism defined here, while historically developing out of an interest in problems of subject search over bodies of disparate material in many media, may be applied to many problems far distant (or so they appear) from the problems of subject indexing for encyclopedias. The terminology continues to reflect the historical origins of the terms, in the interests of clarity and concreteness.
Note that since electronic resources of any kind can themselves become the objects of our attention, they may also be treated as topics. (A picture depicting William Shakespeare, for example, is just an occurrence of the topic representing William Shakespeare, but it might also be mentioned, as a picture, in a history of art, or in a discussion of graphics formats, or in an inventory of digital resources — or in a topic map.)